Thomas Wang* 1, Adam Roberts* 2, Daniel Hesslow3, Teven Le Scao1, Hyung Won Chung2, Iz Beltagy4, Julien Launay3 5, Colin Raffel1
* Equal Contribution, 1 Hugging face, 2 Google, 3 LightOn, 4 Allen institute for AI, 5 LPENS, Ecole Normale Superieure.
Abstract
- (Motivation) Large Language Model (LLM) 이 zero-shot generalization 에 좋은 성능을 보인다. 하지만, 많은 State-of-the-Art 모델들이 각기 다른 architecture 와 pre-training objective 를 통해 학습되는데, 이 요소들에 대한 체계적인 비교(systematic comparison) 이 적다.
- (Solution) 이 논문에서는 여러 LLM 들의 modeling choice 와 zero-shot generalization 에 대한 영향력을 평가하는 large-scale evaluation 방법을 제안한다.
- (Experiment) (causal decoder-only / non-causal decoder-only / encoder-decoder) 세 구조 (architecture) 와 (autoregressive, masked language modeling) 두 가지 pre-training objective, 그리고 with/without multitask finetuning 조합들을 실험을 진행한다.
- (Results) causal decoder-only + autoregressive 방법이 zero-shot 성능은 제일 좋았으나, non-causal + mlm + multi-task finetuning 방법이 실험 성능은 제일 좋았다.
Introduction
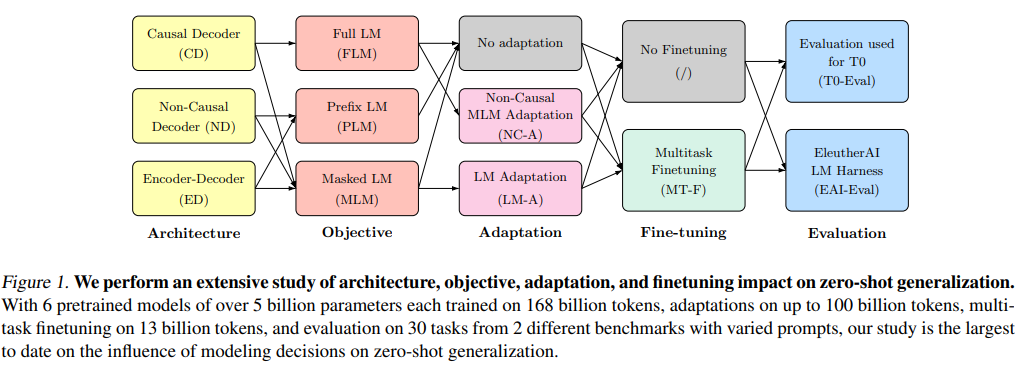
위의 그림의 module 블록들의 색과 아래의 색을 연결
Large Language Model(LLMs) 들은 unstructured text data 에 pre-train 된 후, additional training or labeled data 없이 다양한 방면의 task 에서 좋은 성능을 보인다. 이러한 능력을 zero-shot generalization 이라고 한다. 현재 대부분의 LLM 들은 Transformer architecure 기반으로 구성되어 있다. Original Transformer 는 encoder-decoder 구조로 되어있지만, 많은 최근 LLM 들은 causal decoder-only 모델로, auto-regressive 방법으로 학습한다([1], [2], [3]) 그러나, T5 model 에서는 Encoder-Decoder (ED) model 을 통해 transfer learning 으로 decoder-only LLM 을 outperform 한다. 추가적으로, UniLM 등의 Non-causal decoders-only 구조는 attnetion mask 를 활용하여 decoder-only 와 encoder-decoder model 의 구조 사이의 gap 을 줄인다.
최근의 연구([4],[5],[6])에서는 prompted task 들의 ensemble 의 multitask finetuning stage 을 통해 encoder-decoder model 과 causal decoder-only 모델에서 엄청난 성능향상을 이끌어내었다. 이에 따라, multitask fintuning 의 conjunction 과 architecture choice 의 조합에 따른 zero-shot generalization 성능에 대한 의문점이 제기된다.
Transformer 모델들은 다양한 self-supervised training objective 를 가질 수 있다. 보통, causal decoder-only LLM 들은 full language modeling (FLM) objective 로, encoder-decoder model 은 masked language modeling (MLM) objective 로 학습을 진행한다. MLM 에는 span corruption 등이 포함될 수 있다. 추가적인 downstream task finetuning 에 대해, MLM 의 효과에 대해서는 이미 많은 연구에서 검증이 되었다. 최근 가장 강력한 성능을 보이는 T0 model 역시 MLM 을 사용하였다. 최근, Lester et al. 은 adaptation stage (extending pretraining but with a different objective) 를 소개한다. 이는 MLM 모델을 prompted text generation task 를 수행하는 것을 가능하게 하며, objective 사이의 gap 을 줄여준다.
이러한 결과들은 which architecture and which pre-training objective pair 가 LLM 에 가장 강력한 (strongest) zero-shot generalization capability 를 부여하는지에 대한 의문점을 남긴다. 기존에 이러한 구조와 목적함수 조합에 대한 연구가 있었지만, zero-shot 성능에 관한 연구는 아니었고, 대부분 transfer learning 을 위한 연구([7], [8]) 였다. 또, 추가적으로 최근 multitask finetuning 이 효과적이라는 것이 증명되면서, 어떠한 조합이 multitask finetuning 과 잘 맞을지에 대한 궁금증도 생긴다.
Large-scale systematic study
이 논문에서는 architecture 와 pre-training objectives 의 조합에 따른 zero-shot generalization 의 성능에 대한 실험을 진행한다. 그림에서와 같이, causal decoder-only, noncasual decoder-only, encoder-decoder architecture 들과, full, prefix, mlm 의 여섯 가지 조합으로 실험을 진행한다. 추가적으로, with and without multitask finetuning 역시 평가한다. 실험은 large-scale 로 진행한다. 5 billion parameter (11 billions for encoder-decoder) on 168 billion token 으로 학습하고, multitask finetuning 은 13 billion token 에 수행한다. Evaluation set 으로는 T0-Eval 과 Eleuther AI LM Harness (EAI-Eval) 을 활용하고, 이들은 다양한 prompt 들의 30 개의 downstream task 를 갖고 있다.
Multitask finetuning impacts architecture and objective choice
저자들은 FLM objective 로 학습된 causal-decoder model 이 (GPT-3 와 유사) pre-training 직후 바로 zero-shot 을 잴 때 좋은 성능을 보이는 것을 발견했다. 그러나, multitask finetuning 을 진행한 이후에는 오히려 MLM 으로 학습한 모델이 더 좋은 결과를 보였고, FLM 으로 학습한 causal decoder-only 모델은 좋지 않았다.
Bridging across architectures and objectives with adaptation
여러 조합에 대한 adaptation 으로 두 가지를 고려한다. 첫 번째는 full language modeling adaptation 으로 MLM-trained non-causal decoder model 을 FLM + causal decoder 로 변환한다. 이렇게 할 경우, FLM task 에서 1.6 배 빠르게 수렴을 한다. 두 번째는, non-causal MLM adaptation 으로, FLM + causal decoder 를 MLM + non-causal decoder 로 바꾼다. 이렇게 바꾼 경우, MLM task 에 대해 3.3 배 빠르게 수렴한다. 이러한 adaptation 방법은 new version of model suited for multitask finetuning 을 생산하고, benchmark 에서 두 번째로 좋은 성능의 결과를 보인다.
Background
Transformer
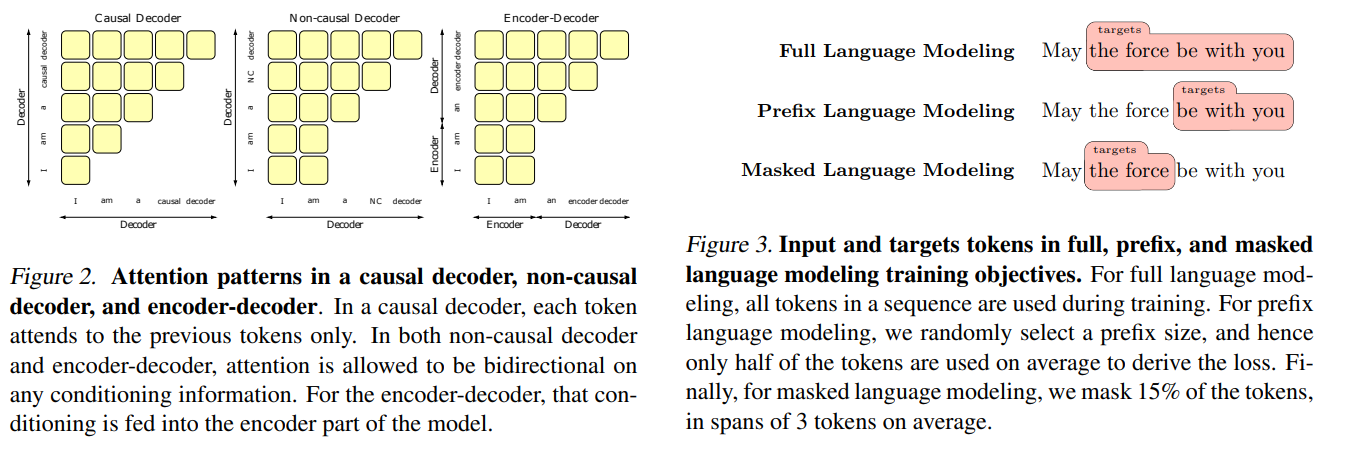
거의 모든 LLM 들은 transformer 기반으로 설계된다. LLM 을 구성하는 데는 여러 기술들이 굉장히 많이 쓰이기 때문에, 다른 것은 제한하고 main architecutre 만 생각했을 때 Transformer block 이 main architecutre 이다. Transformer block 은 multi-head attention, layer normalization, dense two-layer feedforward network, residual connections 로 이루어져 있다.
Encoder-Decoder
Transformer 는 encoder-decoder 구조로 되어있다. Encoder 에서는 input token 을 bidirectional conditioning 을 통해, 모든 input-token 끼리 서로 볼 수 있으며, decoder 에서는 autoregressive 하게 target sequence 를 token-by-token 예측한다. Decoder 의 self-attention layer 에서는 causal masking pattern (그림2 오른쪽) 을 통해 future token 을 보는 것을 방지한다. Encoder-Decoder 구조를 활용하는 Pre-trained Language model (PLM) 에는 BART, T5 등이 있다.
Causal decoder-only
최신 LLM 들은 전부 Transformer variant 이지만, 최신 LLM 들은 decoder-only 구조를 많이 사용한다. Decoder-only 구조는 single text stream 을 input 으로 하여, past token 으로 부터 autoregressive 하게 다음 token 을 예측한다. 이렇게 할 경우, conditioning text 에 대해서는 weaker representation 을 가지지만, generation 과 같은 autoregressive prediction 에는 자연스럽게 잘하는 모델이 된다. GPT series(GPT-1,2,3) 가 이러한 decoder-only 구조 에 속한다.
Non-causal decoder-only
Decoder-only 구조에 input/conditioning text 에 대한 richer representation 을 build 하기 위해, attention mask 수정을 통한 간단한 방법이 제안되었다. self-attention masking pattern 을 그림 2의 중간과 같이 바꿔줌으로써, 구현할 수 있다. 이러한 구조를 prefix Language model ([10])이라고도 한다.
Encoder-only
BERT 와 같이 transfomer encoder block 만 사용하는 경우도 있다. 이러한 경우, NLU task 는 잘 풀지만, NLG task 에 대해서 매우 취약한 모습을 보인다.
Comparisons across architecures
Decoder-only model 은 모든 sequence 를 decoder 에서 처리하고, encoder-decoder 의 경우, input 은 encoder 에서, target 은 decoder 에서 처리한다. 따라서 같은 계산량 을 가져가기 위해서는 encoder-decoder 구조가 decoder 구조보다 두 배의 메모리(파라미터) 를 가지게 된다.
Pre-training objectives
그림 3 에 pre-training objective 에 대한 내용이 있다.
Full Language modeling
GPT-2 이후로, large-scale decoder-only 모델이 autoregressive NLG 에서 좋은 결과를 보인다. FLM 은 이전의 token 들로 부터 바로 다음 token 을 예측하는 modeling 기법이다.
Prefix Language modeling
non-casual decoder-only model 과 encoder-decoder model 들이 Language modeling (LM) 을 수행하기 위해, prefix 를 지정할 수 있다. FLM 과 비슷하게, model 은 이전의 token 들로부터 바로 다음 token 을 예측하지만, prefix 는 고정되어 bidrectional 하게 볼 수 있다. 앞으로 이 논문 소개에서 PLM 은 prefix langugage modeling 을 의미 한다.
Masked Language modeling
Input token 의 일부가 special [Mask] token 으로 대체된 후, 이를 예측하는 modeling 기법이다. 연속되는 token 을 하나의 mask 로 처리하는 span corruption 기술 등이 사용되기도 한다.
Model adaptation
Adaptation 은 기존의 pre-training 기법을 다른 objective, 또는 다른 architecture 로 확장시키는 방법을 의미한다. Fine-tuning 과 다르게, downstream data 가 전혀 사용되지 않으며, only additional pre-training data 만이 사용된다. Language modeling adaptation (LM-A) 는 보통 MLM 으로 학습된 모델을 PLM, FLM 으로 확장시킨다. 이는 MLM 으로 학습된 (NLG 에 약한) encoder-decoder model 을 NLG 에 사용되기 위해 적용된다. 이는 prompt tuning 이 제안되기 전부터 사용된 방법이고, T0 에서 multitask finetuning 전에 model 설계에 사용된다.
Multitask fine-tuning
보통 pre-training 은 web crawling 으로 많은 corpora 를 긁어모은 뒤 학습을 진행한다. 이후, curated high-quality corss-domain data 들에 대해 fine-tuning 을 진행하면, zero-shot generalization 이 좋아지는 것을 확인할 수 있다. MLM + encodeer-decoder model 의 T0 model 과 FLM + causal decoder-only model 에서 multitask fine-tuning 이 zero-shot 성능을 좋게한다는 연구결과를 볼 수 있다. 이들은 task 에 prompt 를 붙여 fine-tuning 을 진행한다. 논문에서는 T- 학습을 위해 사용된 dataset 과 prompt 를 multitask fine-tuning 을 위해 사용한다.
Zero-shot evaluation
Radford et al. 은 처음으로 LLM 들이 zero-shot 성능이 매우 좋다는 것을 보였다. Zero-shot 은 prompting 기술에 의존하는데, 이는 task 를 자연어 형태의 포맷으로 포맷화시키는 것이다. 이 때 사용된 템플릿이 prompt 이다. 불행히도, prompt 에 따라 성능이 sensitive 하게 달라진다. 최근 zero-shot capability 에 대한 주목도가 높아지는 것은 labeld example 이 필요없고, unseen task 에 대해서 fine-tuning 에 대한 complexity 가 사라지기 때문이다.
Methods
모든 <architecture, objective> pair 가 C4 의 168 B token 으로 학습이 된다. 이후, multi-task finetuning 을 고려하여 zero-shot 성능을 측정한다. 또, adaptation 이 architecture/objecdtive 변경으로부터 효과적인 이득을 얻을 수 있는 가능성을 확인한다.
Compute budget guideline
모든 모델은 비슷한 training budget 을 갖게 설계한다. 대략적으로 15petaflops per day 를 갖게 하고, 이는 83만 TPUv4-hours 이다. 메모리는 고려하지 않았다.
Architecture
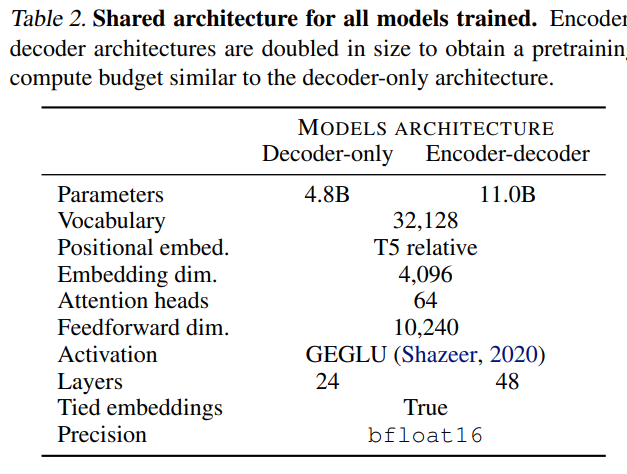
앞서 말한대로 computational cost 를 동일하게 하기 위해, architecture 들이 구성된다. 위의 table 에 자세한 사항이 기록되어 있다.
Pre-training

MLM 은 T5 model 에서 사용한 span corrpution objective 를 사용하였다. Computing budget 을 맞추기 위해, pre-training 에서 loss 계산 시 사용되는 token 수 대신 pre-training 에 사용되는 token 의 수를 조절한다. 예를 들어, Full language modeling 의 경우, 모든 token 이 loss 계산에 사용되고, prefix language modeling 에서 prefix 는 loss 계산에 사용되지 않는다. 평균적으로, FLM 에 비해 PLM 은 반절의 token 이 loss 계산에 사용된다. MLM 의 경우, T5 와 같이 15% 의 input token 이 length 3 의 span mask 로 corrpution 되고, 평균적으로 18% 정도의 token 이 loss 계산에 사용된다.
Multitask finetuning
Pre-training 이후 13B token 으로 구성된 T0 training dataset 에 fine-tuning 한다. Dropout 이 zero-shot 성능에 큰 영향을 미치는 것을 발견하여 추가한다.
Evaluation
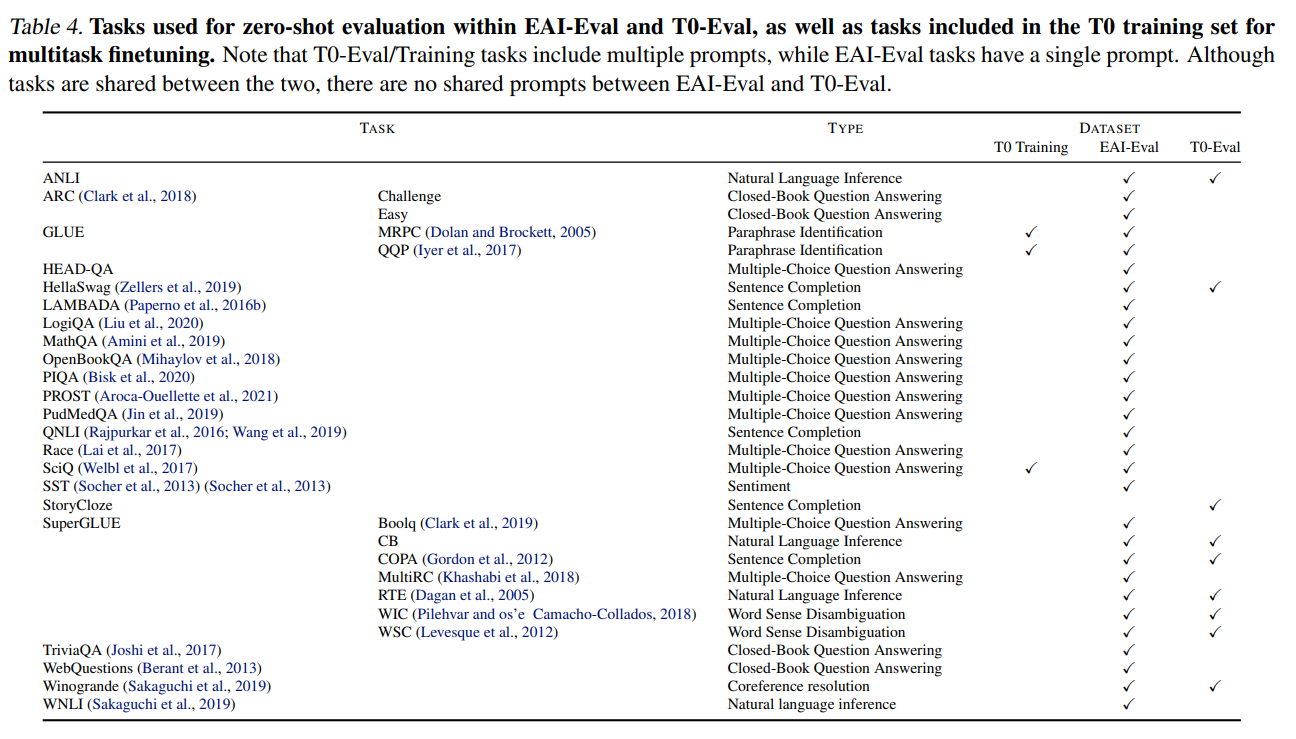 T0-Eval 은 각 task 마다 multiple prompt 를 제공하고, EAI-Eval 은 하나의 태스크당 하나의 prompt 만을 제공한다. T0-Eval 은 prompt 별로 중간값을 취하고, 11 task 에 평균값을 취해 report 하였다. 42B, 84B, 168B token 들에 대해 model checkpoint 를 저장하였다.
T0-Eval 은 각 task 마다 multiple prompt 를 제공하고, EAI-Eval 은 하나의 태스크당 하나의 prompt 만을 제공한다. T0-Eval 은 prompt 별로 중간값을 취하고, 11 task 에 평균값을 취해 report 하였다. 42B, 84B, 168B token 들에 대해 model checkpoint 를 저장하였다.
Experiments
After self-supervised pretraining only
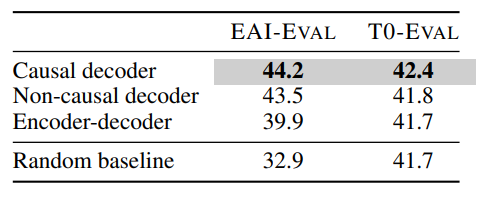 첫 번째로, self-supervised learning 학습 이후 zero-shot 성능을 본다. MLM 은 알맞지 않기 때문에, 사용되지 않았다.
첫 번째로, self-supervised learning 학습 이후 zero-shot 성능을 본다. MLM 은 알맞지 않기 때문에, 사용되지 않았다.
- Causal Decoder-only + FLM 모델이 가장 좋았고, non-causal decoder-only + PLM 가 뒤따르며, encoder-decoder + PLM 는 좋지 못하다.
- T0-Eval 에서의 실험결과는 random-baseline 과 크게 차이가 없지만, EAI-Eval 에서는 차이가 있다.

After multitask finetuning
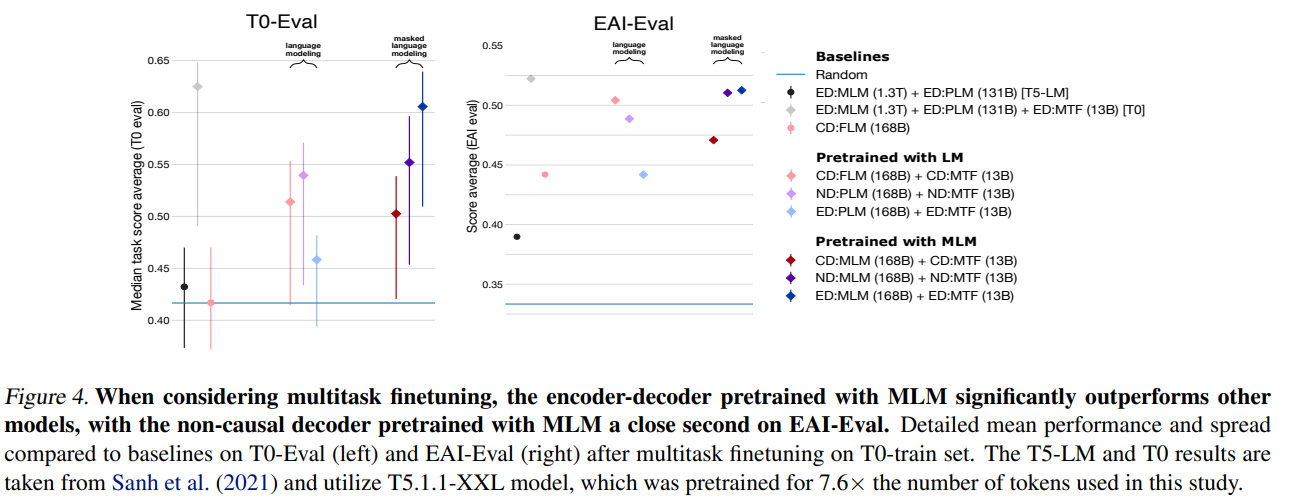
Decoder-only + FLM 구조가 zero-shot 성능은 더 좋고, Encoder-Decoder + MLM 구조가 fine-tuning 이후 성능이 더 좋다는 것이 이미 여러 연구에서 보여졌다. 따라서 저자들은 모든 architecture/objective 조합을 multitask fine-tuning 을 한 뒤 실험을 진행한다. 실험 결과는 위에서 불 수 있다.
- EAI-Eval set 에 대하여, Encoder-Decoder + MLM 의 결과가 가장 좋았고, non-causal decoder with MLM 이 거의 비슷하게 뒤따랐다.
- T0-Eval 에서는 확연한 차이가 나타나는데, Encoder-Decoder + MLM 의 성능이 다른 모델들에 비해 압도적으로 좋았다
- Encoder-decoder + PLM 이 가장 좋지 못한 성능을 보여준다.

Influence of the tasks and prompts used for zero-shot evaluation
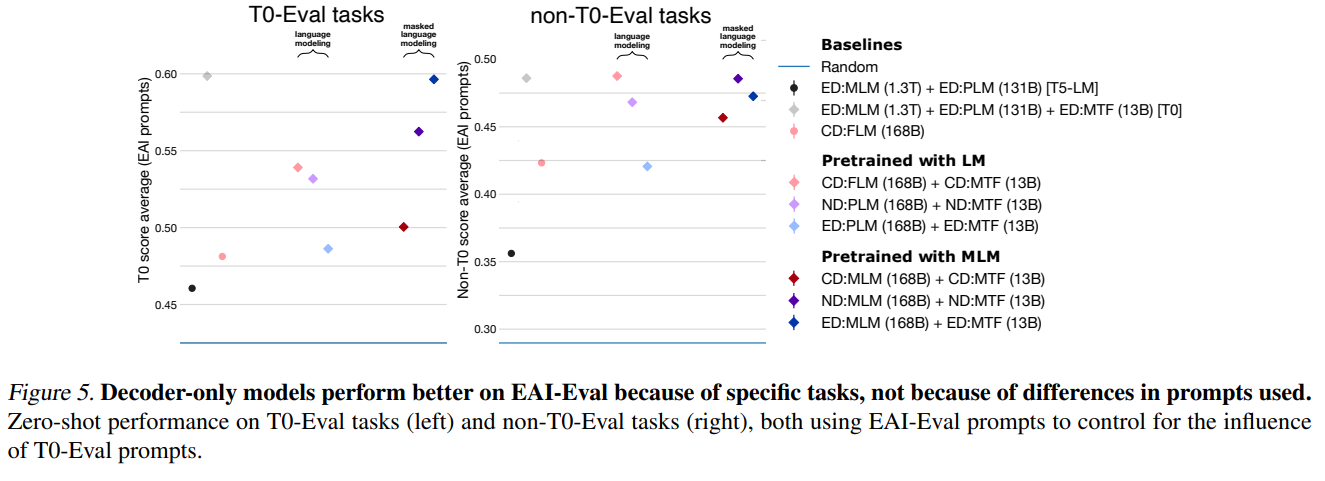
EAI-Eval 과 T0-Eval 은 거의 모든 task 가 겹치는데 (T0-Eval 의 11개 task 중 10 개가 EAI-Eval 에 존재), prompts 는 항상 다르다. EAI-Eval 은 Brown et al. 로 부터, GPT-3 에 최적화된 hand-tuned prompt 를 사용한다. 반면, T0-Eval 은 집단 지성을 통해 각 primary goal 을 높이기 위한 prompt 를 사용한다. 이러한 점에서, EAI-Eval 에서의 결과가 T0-Eval 에서의 결과보다 좋으며, 이는 causal decoder-only + FLM 에서의 without multitask (After self-supervised pretraining only section 의 결과) 에서 도드라지는데, causal decoder-only + FLM model 이 GPT-3 와 거의 유사한 구조이기 때문이다. 따라서, 저자들은 EAI-Eval 에서 사용되는 prompt 를 모든 task 에 적용하여 T0-Eval 에서도 적용하여 보았다. 결과는 위의 그림과 같다. EAI-Eval 과 T0-Eval 에서 겹치는 task 들은 성능이 확 좋아졌다. Prompt 를 빌려주기 전에는 차이가 나는 것에 비하면, prompt 의 효과가 상당하다는 것을 확인할 수 있다. 반면, T0-Eval 에 없는 task 에서 causal decoder performance 가 엄청나게 올라갔고, 특히 LAMBADA 라는 task 에서 매우 큰 차이를 보였다.
Can models be adapted from one architecture/objective to another?
앞선 실험 결과에서, multitask fine-tuning 이 zero-shot 성능 결과에 지대한 영향을 미치는 것을 볼 수 있다. Multitask fine-tuning 을 진행하지 않았을 때는 decoder-only model + FLM 이 zero-shot 성능이 좋았고, multitask fine-tuning 을 진행한 후에는 encoder-decoder + MLM 이 성능이 훨씬 더 좋았다. 이는 불편한 진실을 담고 있는데, multitask fine-tuned encoder-decoder model 은 open-ended generative task 에 잘 맞지 않으며, multitask fine-tuned decoder-only model 은 많은 zero-shot task 에서 best 결과를 보이지 않았다. 이에 저자들은 adaptation 실험을 진행한다.
Language modeling adaptation (LM-A)
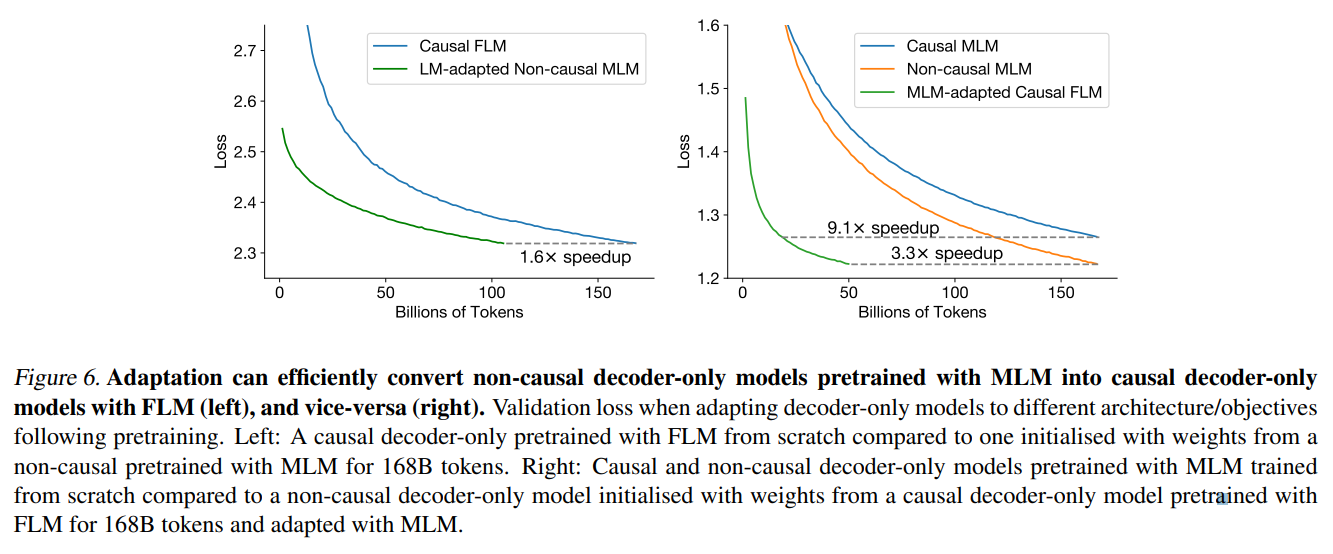
Non-causal decoder-only + MLM -> causal decoder + FLM 으로 adaptation 한다. 이 adaptation 은 simple 한데, architecture 구조는 그대로 두고, attention mask 만 변경하면 된다. 실험 결과, Validation loss 기준으로 같은 성능을 보이는데 168B token 을 봐야하던 것에서, 105B 로 줄어들어 1.6 배 빨라진 것을 알 수 있다.
Non-causal masked language modeling adaptation(NC-A)
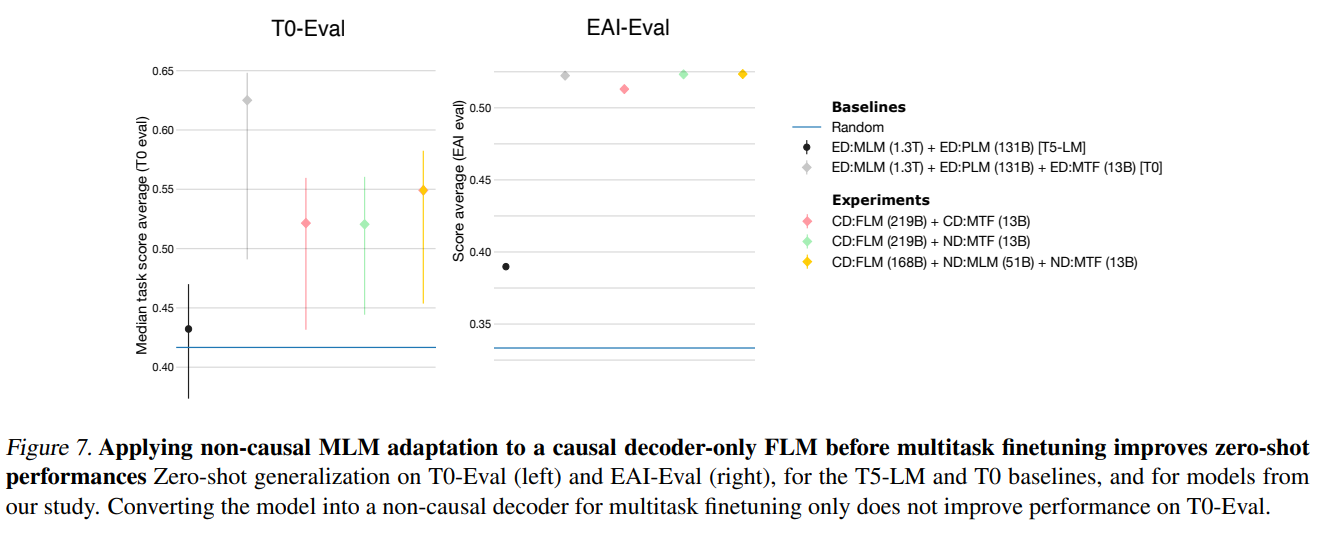 이번엔 새로운 adaptation 방법을 소개한다. : non-causal masked language modeling 기법이다. Causal decoder-only + FLM -> non-causal decoder-only + MLM 으로 adaptation 시킨다. 이는 위의 Language modeling adaptation (LM-A) 의 역과정과 같으며, 방법은 역시 단순하게 attention mask 를 변형시킴으로써 구현 가능하다. Validation Loss 는 Figure 6. 의 오른쪽에서 볼 수 있다. 기존의 MLM 기반의 decoder-only 모델들보다 3.3배 내지 9.1 배 빠르게 수렴한다. 이 adaptation 방법으로 single model 의 1.3 배 cost 만으로 zero-shot model 과 excellent generative model 을 얻는 것이 가능하다.
이번엔 새로운 adaptation 방법을 소개한다. : non-causal masked language modeling 기법이다. Causal decoder-only + FLM -> non-causal decoder-only + MLM 으로 adaptation 시킨다. 이는 위의 Language modeling adaptation (LM-A) 의 역과정과 같으며, 방법은 역시 단순하게 attention mask 를 변형시킴으로써 구현 가능하다. Validation Loss 는 Figure 6. 의 오른쪽에서 볼 수 있다. 기존의 MLM 기반의 decoder-only 모델들보다 3.3배 내지 9.1 배 빠르게 수렴한다. 이 adaptation 방법으로 single model 의 1.3 배 cost 만으로 zero-shot model 과 excellent generative model 을 얻는 것이 가능하다.
마지막으로, validation loss 의 improvement 가 zero-shot improvement 로 이어지는 것에 대한 실험 결과이다. 저자들은 adapted non-causal + MLM 모델이 기존의 causal + FLM 보다 zero-shot 성능이 더 좋은 것을 확인했다. 실험은 causal decoder + FLM with 219B tokens before multitask fine-tuning, causal decoder + FLM with 219B tokens after mulitask fine-tuning, causal decoer + FLM with 168 tokens + MLM-adapted as an non causal for 51B token after multitask fine-tuned. 세 모델에 대해서 진행하고, 이후 세 모델은 13B tokens 으로 한 번 더 multitask fine-tuning 을 진행하였다. 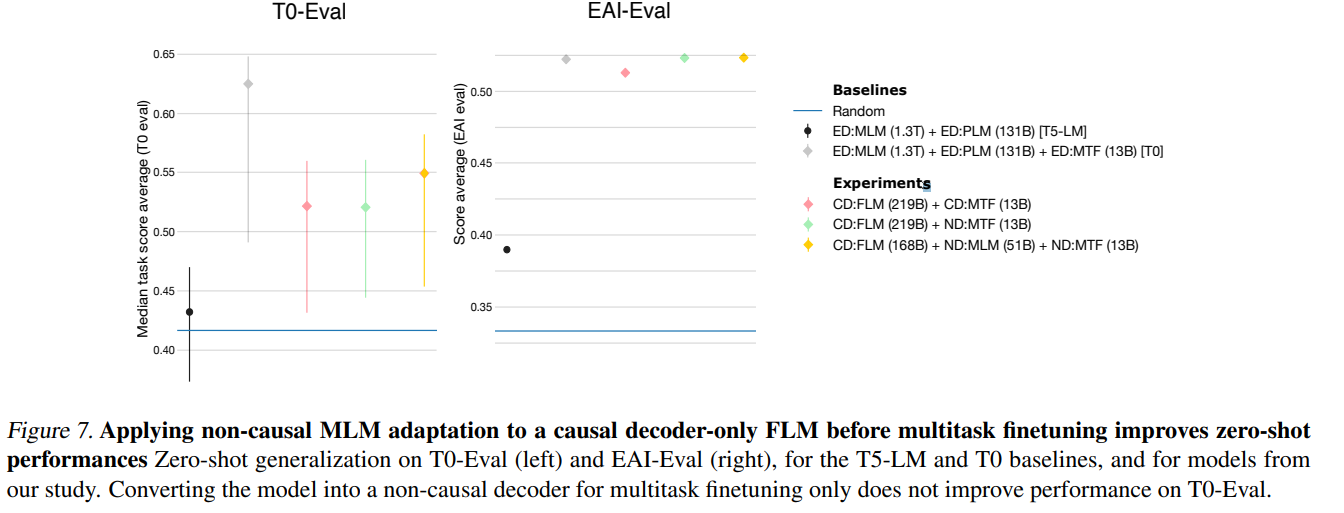
결과는 위와 같고, Adaptation 의 효과가 매우 좋은 것을 볼 수 있다.
