Yan Zeng1, Xinsong Zhang Chaganty1, Hang Li1
1ByteDance AI Lab. Correspondence to: Yan Zeng.

Abstract
- 기존의 Vision-and-Language 방법들은 object detection 을 이용한 object-centric feature 에 의존하여 학습됨.
- 이러한 방법으로는 multiple object 들의 relation 을 배우기 어렵다는 단점이 있음.
- 본 논문에서는 multi-granularity 를 통해 이 문제를 해결하여, state-of-the-art 를 달성함.
Introduction
현재 Vision-Language task 들은 대부분 Pre-trained Vision-Language Model (VLM) 의 fine-tuning 을 통해 좋은 성능을 보이고 있다. 현재 방법들은 대부분 위의 그림의 (a), (b) 의 두 approach 를 활용한다. 첫 번째 (a) 의 경우, object detction 모델을 미리 활용하여 object 를 뽑아놓거나 ([1], [2], [3]) on-the-fly 로 object detection 을 활용 ([4], [5])하여 fine-grained (object-centric) feature 와 text 를 align 한다. 그리고 두 번째 (b) 의 경우, object detection 을 활용하지 않고, coarse-grained (overall) feature 와 text 를 align 하여 학습([6], [7], [8])을 한다. 두 방법 모두 단점이 존재하는데, fine-grained 의 경우, 몇몇의 detected object 들이 text 와 관련이 없고, multiple object 들의 서로간의 relation 을 잡아내기 어렵다. 그리고, 모든 downstream task 에 맞춰 카테고리를 pre-define 하기 어렵다. 한편, coarse-grained 의 경우, object-level feature 를 배울 수 없기 때문에, visual reasoning, visual grounding, 그리고 image captioning 과 같은 downstream task 에 대하여 좋지 못한 성능을 보인다. 이 논문에서는 두 방법의 장점을 취하기 위해 obejct-level 과 image-level 에 국한되지 않은 multi-grained alignment 방법을 제안 한다.
본 논문에서는 위의 그림과 같이 multi-grained vision-language pre-trianing 방식을 위해, 세 가지 방향으로 trainign data 를 구성한다: 1) 전체 이미지를 설명하는 image caption, 2) “man wearing backpack” 과 같이 region 을 설명하는 region description, 그리고 3) “backpack” 과 같은 detector 가 찾아낸 object label. 따라서 training data reformulation 을 통해, 하나의 image-text pair 가 여러 image (region) 과 여러 text label 을 갖게 변형되고, “visual concept” 이라는 개념은 이 논문에 한해 object, region, 그리고 image 를 모두 설명하는 개념이 된다.
제안되는 X-VLM 모델은, two-stream 구조로, image encoder, text encoder 그리고 fusion cross-modal encoder 로 구성된다. X-VLM 의 학습은 두 가지 Loss 로 진행된다: 1) visual concept 을 associated text 에 따라 location 시키는 box-regression, IOU loss 2) text 를 visual concept 에 align 시키는 contrastive loss, matching loss, Masked Language Modeling(MLM) loss.
X-VLM 은 여러 가지 downstream task 에서 강력한 성능을 보인다. image-text retrieval 에서 VinVL 모델보다 4.65% 높은 성능 (R@1 on MSCOCO) 을 보였고, ALIGN, ALBEF, 그리고 METER 와 같은 최신 transformer 기반 모델보다 좋은 성능을 보인다. Visual Reasoning task 에서는 VinVL 보다 VQA 에서 0.79%, NLVR2 에서 1.06% 높은 성능을 보인다. 심지어 1.8B 의 거대한 in-house data 로 학습한 $SimVLM_{base}$ 보다도 높은 성능을 보였다. Visual Grounding 에서는 UNITER 보다 4.5% 향상, MDETR 보다 1.1% 향상을 이루어 냈다. Captioning 에서는 $SimVLM_{base}$ 과 유사한 성능을 보여주었다.
Method
 X-VLM 은 two-stream framework 로, image encoder ($I_{trans}$), text encoder ($T_{trans}$), 그리고 cross-modal encoder ($X_{trans}$) 세 가지로 이뤄져 있다. 세 encoder 모두 transformer 를 기반으로 한다. 저자들은 pre-training dataset 을 bounding box 와 associated text 가 있는 region, object 로 나누었고, $(I, T, {(V^j, T^j)}^N ) $ 으로 표기한다. 어떠한 경우 associated text 가 없어 T 가 NaN 일 때도 있고, bounding box 가 없어 N=0 일 때도 있다. 해당하는 boudning box $b_j$ 는 (cx, cy, w, h) 로 normalize 된다. 전체 image itself 의 bounding box $b$ = (0.5, 0.5, 1, 1) 이 된다.
X-VLM 은 two-stream framework 로, image encoder ($I_{trans}$), text encoder ($T_{trans}$), 그리고 cross-modal encoder ($X_{trans}$) 세 가지로 이뤄져 있다. 세 encoder 모두 transformer 를 기반으로 한다. 저자들은 pre-training dataset 을 bounding box 와 associated text 가 있는 region, object 로 나누었고, $(I, T, {(V^j, T^j)}^N ) $ 으로 표기한다. 어떠한 경우 associated text 가 없어 T 가 NaN 일 때도 있고, bounding box 가 없어 N=0 일 때도 있다. 해당하는 boudning box $b_j$ 는 (cx, cy, w, h) 로 normalize 된다. 전체 image itself 의 bounding box $b$ = (0.5, 0.5, 1, 1) 이 된다.
Vision Encoding
multi-grained visual concept 을 생산하기 위해, visual encoder 가 구성된다. Vision transformer 를 기반으로 하는 이 encoder 는 image 를 non-overlapping patch 로 split 한 후, 모든 patch 를 linearly embedding 한다. 224 x 224 resolution 의 image 가 32 x 32 patch 로 embdding 되어, 총 49 개의 patch 가 생산된다. 각 patch $v_{p_i}$ 는 corresponding patch information $p_i$ 를 갖는다. 그림의 왼쪽에서와 같이, Vision Transformer 통과 후, patch feature 는 position information 을 keeping 한 채, {$v_{p_1^j},…,v_{p_M^j}$}$\cdot${$p_1^j, …, p_M^j$} 의 형태로 reshape 되어 $V_j$ 를 이룬다. 이후 $v_{cls}^j$ 로 denote 되는 feature average 값이 prepend 된다. 이러한 방법으로 image encoder 는 $N+1$ 개의 concept representation 을 생성한다. $I_{trans}(V^0)$ 는 모든 patch 정보가 활용된 image representation 이다.
Bounding Box Prediction
언급한대로 multi-granularity 에 대해, visual concept 을 corresponding text 에 locating 시키는 것과 동시에, text 를 visual concept 에 align 시키는 방법으로 모델이 학습된다. 그림의 bounding box stream 과 같이, cross-modal encoder 의 [CLS] token embedding 에 MLP head 를 붙여 학습된다. 
보통 bounding box 는 L1 loss 를 통해 학습되지만, scale 문제에 민감하기 때문에, IOU loss 를 결합하여 scale-invariant 한 loss 를 구성하여 학습한다. 
Contrastive Learning
주어지는 (visual concept, text) pair 에 대해, in-batch contrastive loss 를 구성해 cross-modal encoder 를 학습한다. Multi-granularity 에 대해 해당 visual concept 은 object, region, image 를 모두 포함한다. score function $s(V,T)$ 는 cosine similarity 이고, 각각 [CLS] token embedding 이 score 측정을 위해 사용된다. 

위는 각각 vision-to-text, text-to-vision similarity 식이고, $\tau$ 는 learnable temperature parameter 이다. 최종적으로, 아래와 같이 contrastive loss 를 구성한다. 
H 는 cross entropy loss 이다.
이 loss 의 이해를 위해 기존 CLIP model 의 contrastive loss 구성을 위한 그림을 첨부한다. 
Matching Prediction
위의 contrastive loss 를 구성하기 위한 hard negative sample 을 하나 추출해와, matching prediction 을 진행한다.

Masked Language Modeling
각 word token 이 25% 확률로 선택되고, 선택된 mask token 은 80% 확률로 [MASK], 10% 확률로 random token 으로 바뀌고, 10% 확률로 바뀌지 않는다. 이렇게 구성된 maksed sentence $\hat{T}$ 에 대해, MLM 을 위해 cross-entropy loss 가 구성된다.

최종적인 loss 는 다음과 같다.

Experiment
Pre-training Datasets

Image-Text Retrieval

Visual Reasoning(VQA and NVLR2), Visual Grounding and Image Captioning

Grad-CAM visualization

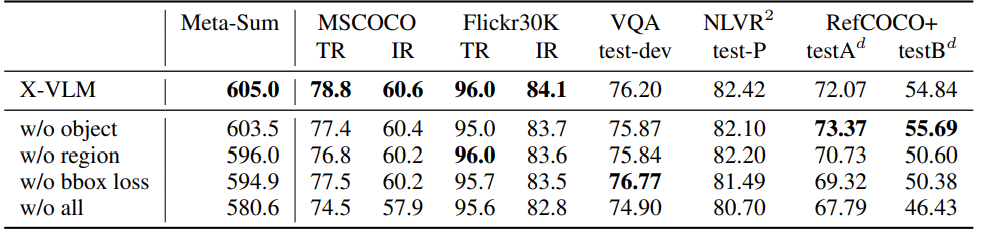
Ablation Study
Conclusion
quoted from paper
- We propose performing multi-grained vision language pre-training to handle the alignments between texts and visual concepts.
- We propose to optimize the model (X-VLM) by locating visual concepts in the image given the associated texts and in the meantime aligning the texts with the visual concepts, where the alignments are in multigranularity.
- We empirically verify that our approach effectively leverages the learned multi-grained alignments in finetuning. X-VLM consistently outperforms existing state-of-the-art methods on many downstream V+L tasks.